文章詳情頁
python - 使用readlines()方法讀取文件內容后,再用for循環遍歷文件與變量匹配時出現疑難?
瀏覽:159日期:2022-09-06 08:17:44
問題描述
with open(’password’, ’r’, encoding=’utf-8’) as f:
print(f.readlines())for i in f.readlines(): if i == ’abc:cba’:breakelse: print(’none’)
這是password文件: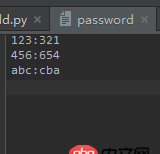
想起到的作用是for循環時,匹配到對應的值就跳出循環,但是每次都沒法匹配到。下圖是輸出結果
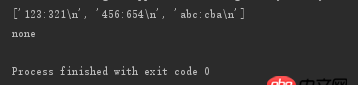
問題解答
回答1:你代碼根本地方錯了 剛才我沒看清楚
with open(’password’, ’r’, encoding=’utf-8’) as f: print(f.readlines()) print(f.readlines())
第二次直接是 []
讀文件指針已經移動到底了 所以第二次沒內容了啊
with open(’password’, ’r’, encoding=’utf-8’) as f: # print(f.readlines()) # print(f.readlines()) readlines = f.readlines() print(readlines) for i in readlines:if i.strip() == ’abc:cba’: break else:print(’none’)
這樣就可以了
排行榜

 網公網安備
網公網安備