文章詳情頁
python - scrapy運行爬蟲一打開就關閉了沒有爬取到數據是什么原因
瀏覽:74日期:2022-08-05 15:09:38
問題描述
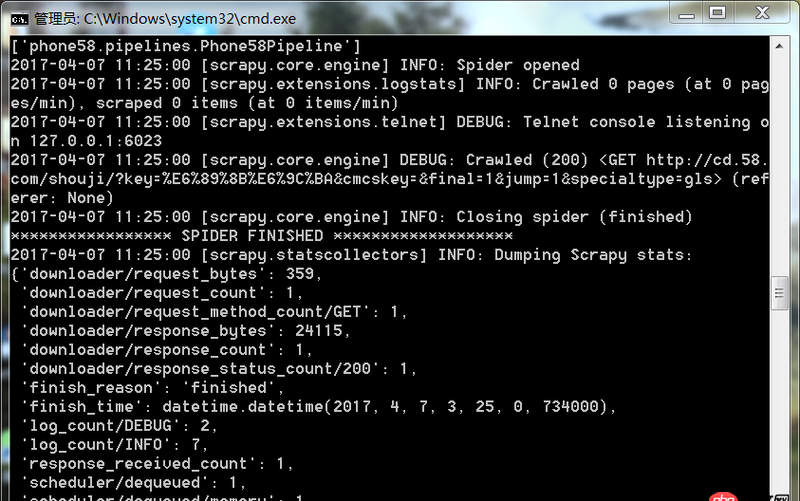
爬蟲運行遇到如此問題要怎么解決
問題解答
回答1:很可能是你的爬取規則出錯,也就是說你的spider代碼里面的xpath(或者其他解析工具)的規則錯誤。導致沒爬取到。你可以把網址print出來,看看是不是[]
相關文章:
1. 在mybatis使用mysql的ON DUPLICATE KEY UPDATE語法實現存在即更新應該使用哪個標簽?2. 哭遼 求大佬解答 控制器的join方法怎么轉模型方法3. mysql儲存json錯誤4. mysql - 怎么生成這個sql表?5. mysql - 數據庫表中,兩個表互為外鍵參考如何解決6. Navicat for mysql 中以json格式儲存的數據存在大量反斜杠,如何去除?7. sql語句 - 如何在mysql中批量添加用戶?8. mysql - 表名稱前綴到底有啥用?9. 編輯成功不顯示彈窗10. 怎么php怎么通過數組顯示sql查詢結果呢,查詢結果有多條,如圖。
排行榜
 網公網安備
網公網安備