文章詳情頁
SQL Server刪除表中的重復(fù)數(shù)據(jù)
瀏覽:31日期:2023-03-06 14:25:22
添加示例數(shù)據(jù)
create table Student(ID varchar(10) not null,Name varchar(10) not null,);insert into Student values("1", "zhangs");insert into Student values("2", "zhangs");insert into Student values("3", "lisi");insert into Student values("4", "lisi");insert into Student values("5", "wangwu");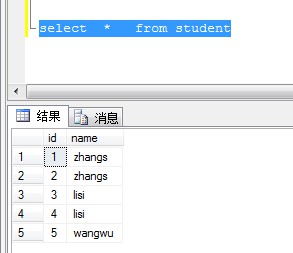
刪除Name重復(fù)多余的行,每個Name僅保留1行數(shù)據(jù)
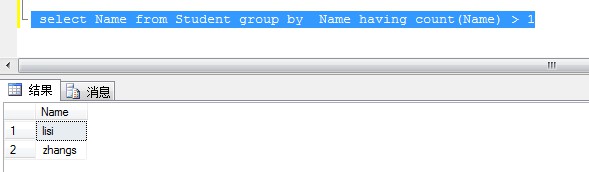
1、查詢表中Name 重復(fù)的數(shù)據(jù)
select Name from Student group by Name having count(Name) > 1
2、有唯一列,通過唯一列最大或最小方式刪除重復(fù)記錄
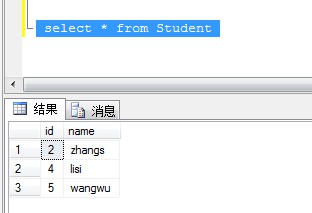
檢查表中是否有主鍵或者唯一值的列,當(dāng)前可以數(shù)據(jù)看到ID是唯一的,可以通過Name分組排除掉ID最大或最小的行
delete from Student where Name in( select Name from Student group by Name having count(Name) > 1) and ID not in(select max(ID) from Student group by Name having count(Name) > 1 )
執(zhí)行刪除腳本后查詢
3、無唯一列使用ROW_NUMBER()函數(shù)刪除重復(fù)記錄
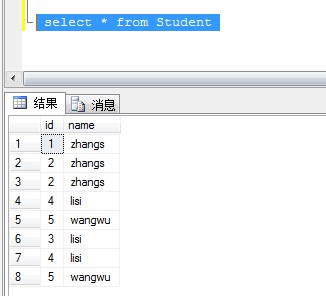
如果表中沒有唯一值的列,可以通過row_number 來刪除重復(fù)數(shù)據(jù)
重復(fù)執(zhí)行插入腳本,查看表數(shù)據(jù),表中沒有唯一列值
Delete T From (Select Row_Number() Over(Partition By [Name] order By [ID]) As RowNumber,* From Student)T Where T.RowNumber > 1
小知識點
語法:ROW_NUMBER() OVER(PARTITION BY COLUMN ORDER BY COLUMN)
表示根據(jù)COLUMN分組,在分組內(nèi)部根據(jù) COLUMN排序,而此函數(shù)計算的值就表示每組內(nèi)部排序后的順序編號(組內(nèi)連續(xù)的唯一的)
函數(shù)“Row_Number”必須有 OVER 子句。OVER 子句必須有包含 ORDER BY
Row_Number() Over(Partition By [Name] order By [ID]) 表示已name列分組,在每組內(nèi)以ID列進行升序排序,每組內(nèi)返回一個唯一的序號
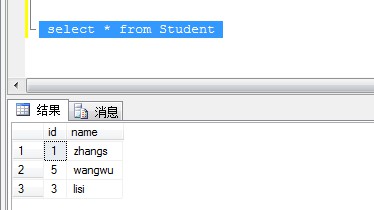
執(zhí)行刪除腳本后查詢表數(shù)據(jù)
到此這篇關(guān)于SQL Server刪除表中重復(fù)數(shù)據(jù)的文章就介紹到這了。希望對大家的學(xué)習(xí)有所幫助,也希望大家多多支持。
標簽:
MsSQL
相關(guān)文章:
1. SQL Server全文檢索簡介2. SQL SERVER數(shù)據(jù)庫開發(fā)之存儲過程的應(yīng)用3. 在SQL Server 2005修改存儲過程4. idea連接SQL Server數(shù)據(jù)庫的詳細圖文教程5. SQL Server主鍵與外鍵設(shè)置以及相關(guān)理解6. SQL Server中搜索特定的對象7. SQL Server數(shù)據(jù)庫連接查詢和子查詢實戰(zhàn)案例8. SQL SERVER中的流程控制語句9. SQL Server跨服務(wù)器操作數(shù)據(jù)庫的圖文方法(LinkedServer)10. SQL Server中T-SQL標識符介紹與無排序生成序號的方法
排行榜
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備