使用python-cv2實(shí)現(xiàn)Harr+Adaboost人臉識(shí)別的示例
Haar特征
哈爾特征使用檢測(cè)窗口中指定位置的相鄰矩形,計(jì)算每一個(gè)矩形的像素和并取其差值。然后用這些差值來(lái)對(duì)圖像的子區(qū)域進(jìn)行分類。
haar特征模板有以下幾種:
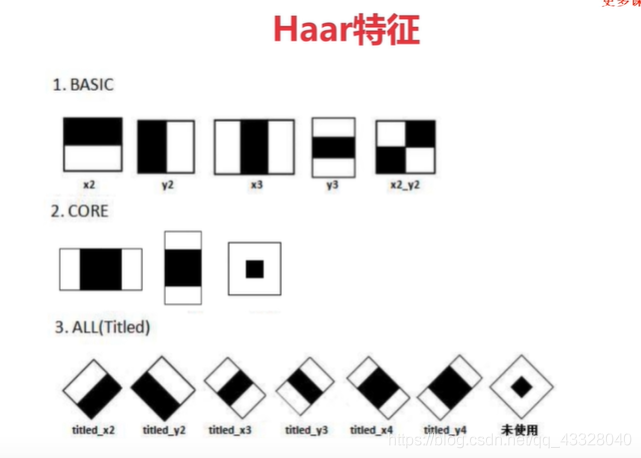
以第一個(gè)haar特征模板為例

計(jì)算方式
1.特征 = 白色 - 黑色(用白色區(qū)域的像素之和減去黑色區(qū)域的象征之和)
2.特征 = 整個(gè)區(qū)域 * 權(quán)重 + 黑色 * 權(quán)重
使用haar模板處理圖像
從圖像的起點(diǎn)開始,利用haar模板從左往右遍歷,從上往下遍歷,并設(shè)置步長(zhǎng),同時(shí)考慮圖像大小和模板大小的信息
假如我們現(xiàn)在有一個(gè) 1080 * 720 大小的圖像,10*10 的haar模板,并且步長(zhǎng)為2,那么我我們所需要的的計(jì)算量為: (1080 / 2 * 720 / 2) * 100 * 模板數(shù)量 * 縮放 約等于50-100億,計(jì)算量太大。
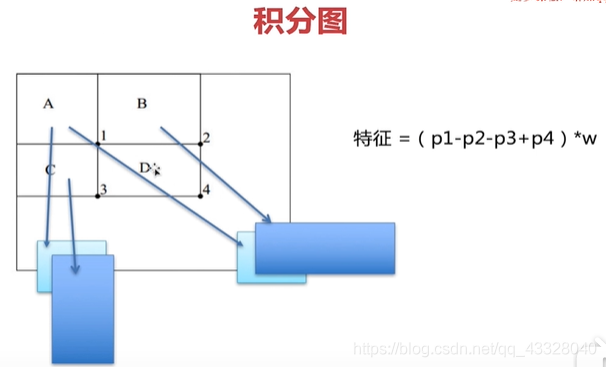
積分圖
使用積分圖可大量減少運(yùn)算時(shí)間,實(shí)際上就是運(yùn)用了前綴和的原理
Adaboost分類器
Adaboost是一種迭代算法,其核心思想是針對(duì)同一個(gè)訓(xùn)練集訓(xùn)練不同的分類器(弱分類器),然后把這些弱分類器集合起來(lái),構(gòu)成一個(gè)更強(qiáng)的最終分類器(強(qiáng)分類器)。
算法流程
該算法其實(shí)是一個(gè)簡(jiǎn)單的弱分類算法提升過(guò)程,這個(gè)過(guò)程通過(guò)不斷的訓(xùn)練,可以提高對(duì)數(shù)據(jù)的分類能力。整個(gè)過(guò)程如下所示:
1. 先通過(guò)對(duì)N個(gè)訓(xùn)練樣本的學(xué)習(xí)得到第一個(gè)弱分類器;2. 將分錯(cuò)的樣本和其他的新數(shù)據(jù)一起構(gòu)成一個(gè)新的N個(gè)的訓(xùn)練樣本,通過(guò)對(duì)這個(gè)樣本的學(xué)習(xí)得到第二個(gè)弱分類器 ;3. 將1和2都分錯(cuò)了的樣本加上其他的新樣本構(gòu)成另一個(gè)新的N個(gè)的訓(xùn)練樣本,通過(guò)對(duì)這個(gè)樣本的學(xué)習(xí)得到第三個(gè)弱分類器;4. 最終經(jīng)過(guò)提升的強(qiáng)分類器。即某個(gè)數(shù)據(jù)被分為哪一類要由各分類器權(quán)值決定。
我們需要從官網(wǎng)下載倆個(gè)Adaboost分類器文件,分別是人臉和眼睛的分類器:下載地址:https://github.com/opencv/opencv/tree/master/data/haarcascades
代碼實(shí)現(xiàn)
實(shí)現(xiàn)人臉識(shí)別的基本步驟:
1.加載文件和圖片 2.進(jìn)行灰度處理 3.得到haar特征 4.檢測(cè)人臉 5.進(jìn)行標(biāo)記
我們使用cv2.CascadeClassifier()來(lái)加載我們下載好的分類器。
然后我們使用detectMultiScale()方法來(lái)得到識(shí)別結(jié)果
import cv2import numpy as npimport matplotlib.pyplot as plt# 1.加載文件和圖片 2.進(jìn)行灰度處理 3.得到haar特征 4.檢測(cè)人臉 5.標(biāo)記face_xml = cv2.CascadeClassifier(’haarcascade_frontalface_default.xml’)eye_xml = cv2.CascadeClassifier(’haarcascade_eye.xml’)img = cv2.imread(’img.png’)cv2.imshow(’img’, img)gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)# 1.灰色圖像 2.縮放系數(shù) 3.目標(biāo)大小faces = face_xml.detectMultiScale(gray, 1.3, 5)print(’face = ’,len(faces))print(faces)#繪制人臉,為人臉畫方框for (x,y,w,h) in faces: cv2.rectangle(img, (x,y), (x + w, y + h), (255,0,0), 2) roi_face = gray[y:y+h,x:x+w] roi_color = img[y:y+h,x:x+w] eyes = eye_xml.detectMultiScale(roi_face) print(’eyes = ’,len(eyes)) for (ex,ey,ew,eh) in eyes: cv2.rectangle(roi_color, (ex,ey),(ex + ew, ey + eh), (0,255,0), 2)cv2.imshow(’dat’, img)cv2.waitKey(0)
face = 1[[133 82 94 94]]eyes = 2
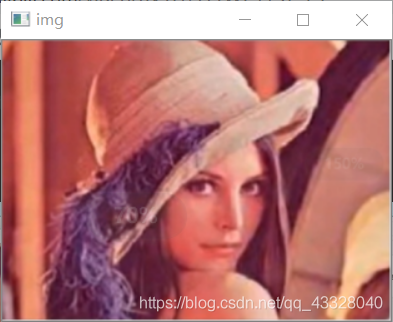
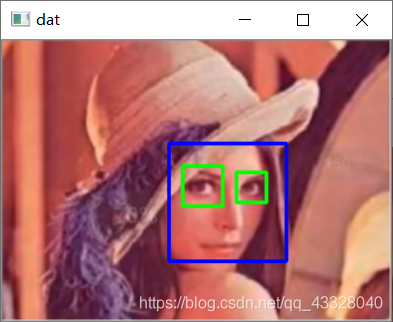
到此這篇關(guān)于使用python-cv2實(shí)現(xiàn)Harr+Adaboost人臉識(shí)別的示例的文章就介紹到這了,更多相關(guān)python cv2 人臉識(shí)別內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. 使用Docker的NFS-Ganesha鏡像搭建nfs服務(wù)器的詳細(xì)過(guò)程2. VMware中如何安裝Ubuntu3. IntelliJ IDEA設(shè)置背景圖片的方法步驟4. IntelliJ IDEA刪除類的方法步驟5. 刪除docker里建立容器的操作方法6. docker /var/lib/docker/aufs/mnt 目錄清理方法7. IntelliJ IDEA導(dǎo)入項(xiàng)目的方法8. IntelliJ IDEA設(shè)置默認(rèn)瀏覽器的方法9. IntelliJ IDEA調(diào)整字體大小的方法10. Docker 部署 Prometheus的安裝詳細(xì)教程
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備