python實(shí)現(xiàn)三種隨機(jī)請(qǐng)求頭方式
相信大家在爬蟲中都設(shè)置過請(qǐng)求頭 user-agent 這個(gè)參數(shù)吧? 在請(qǐng)求的時(shí)候,加入這個(gè)參數(shù),就可以一定程度的偽裝成瀏覽器,就不會(huì)被服務(wù)器直接識(shí)別為spider.demo.code ,據(jù)我了解的,我很多讀者每次都是直接從network 中去復(fù)制 user-agent 然后把他粘貼到代碼中, 這樣獲取的user-agent 沒有錯(cuò),可以用, 但是如果網(wǎng)站反爬措施強(qiáng)一點(diǎn),用固定的請(qǐng)求頭可能就有點(diǎn)問題, 所以我們就需要設(shè)置一個(gè)隨機(jī)請(qǐng)求頭,在這里,我分享一下我自己一般用的三種設(shè)置隨機(jī)請(qǐng)求頭方式
思路介紹:其實(shí)要達(dá)到隨機(jī)的效果,很大程度上我們可以利用隨機(jī)函數(shù)庫(kù)random 這個(gè)來實(shí)現(xiàn),可以調(diào)用random.choice([user-agent]) 隨機(jī)pick數(shù)組中一個(gè)就可以了,這是我的一種方式。
python作為一個(gè)擁有眾多第三方包的語(yǔ)言,自然就有可以生成隨機(jī)請(qǐng)求頭的包咯,沒錯(cuò),就是fake-useragent 這個(gè)第三方庫(kù)了,稍后我們介紹一下這個(gè)函數(shù)庫(kù)的簡(jiǎn)單使用。
既然別人可以寫第三方庫(kù),自然自己也可以實(shí)現(xiàn)一個(gè)這樣的功能,大部分情況下,我很多代碼都是直接調(diào)用我自己實(shí)現(xiàn)的一個(gè)GetUserAgentCS 類,直接就可以獲取一個(gè)隨機(jī)請(qǐng)求頭了,直接寫函數(shù)庫(kù),才牛逼舒服, 這個(gè)我也會(huì)在下面介紹如何編寫函數(shù)庫(kù)。
自己編寫第三方庫(kù):不知道你們寫代碼的框架是怎樣的,面向過程還是面向?qū)ο螅?對(duì)于一次性的代碼,就簡(jiǎn)單的編碼就行了,如果你覺得這個(gè)代碼它可以會(huì)在很多的地方用得到,可以重復(fù)使用,那么你就可以使用類的方式,去編寫這個(gè)代碼,那么在其他的文件中,你就可以直接調(diào)用你的寫這個(gè)文件,直接調(diào)用你寫的class類中的各種方法,而我也是這樣實(shí)現(xiàn)的一個(gè)隨機(jī)請(qǐng)求頭的一個(gè)第三方庫(kù), 如下:
import randomimport csvclass GetUserAgentCS(object): ''' 調(diào)用本地請(qǐng)求頭文件, 返回請(qǐng)求頭 ''' def __init__(self): with open(’D://pyth//scrapy 項(xiàng)目//setting//useragent.csv’, ’r’) as fr: fr_csv = csv.reader(fr) self.user_agent = [str(i[1]) for i in fr_csv] def get_user(self): return random.choice(self.user_agent)
useragent文件如下:
1,'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'2,'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36'3,'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'4,'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; CrOS i686 3912.101.0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36'5,'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36'-------------- # too much 100...
代碼很簡(jiǎn)單的,讀取本地的csv文件,然后random一個(gè)出去就行了,那現(xiàn)在就有人問我,你這個(gè)文件怎么來的, 很簡(jiǎn)單啊,自然就有方法了,待會(huì)在下一個(gè)模塊我會(huì)講到,在這里,我們只需要編寫一個(gè)GetUserAgentCS類就可以,代碼可以直接抄我上面的,然后保存為get_useragent.py 就可以了,然后你把這個(gè)包文件放在你自己爬蟲文件夾的地方,然后這樣調(diào)用:
from get_useragent import GetUserAgentCSheaders = {}ua = GetUserAgentCS().get_user()headers[’user-agent’] = uareturn headers
如果你在這個(gè)調(diào)用GetUserAgentCS 不成功, 或者底下會(huì)出現(xiàn)紅色的波浪線, 那么就是你沒有設(shè)置當(dāng)前工作環(huán)境,你只需要這么設(shè)置(設(shè)置你的爬蟲文件夾):
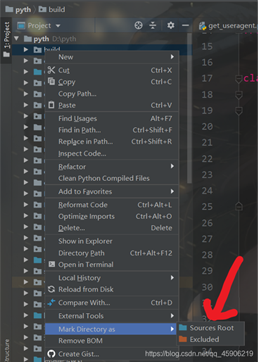
你需要點(diǎn)擊 Sources Root 就可以了!
使用第三方庫(kù) fake-useragent:這是一個(gè)別人已經(jīng)寫好的第三方庫(kù),你需要安裝然后調(diào)用API 就可以了, 它可以獲取各種的請(qǐng)求頭,唯一的缺點(diǎn)就是 請(qǐng)求不穩(wěn)定,有的時(shí)候網(wǎng)絡(luò)波動(dòng)就可能導(dǎo)致獲取不成功,用于Scrapy中,不是很舒服,所以我在這個(gè)包的基礎(chǔ)上,編寫了如上我自己的包,至于請(qǐng)求頭的數(shù)據(jù)怎么來的, 就是在這個(gè)包運(yùn)行正常時(shí)候,一直更改user-agent,然后不斷的請(qǐng)求 http://httpbin.org/user-agent 然后不斷的保存數(shù)據(jù),寫入本地文件就可以了。
我們還是講一講這個(gè)包的使用方式吧!
安裝
pip install fake-useragent
你可以 pip list 查看一下 是否安裝成功
使用方式
from fake_useragent import UserAgentheaders= {’User-Agent’:str(UserAgent().random)}r = requests.get(url, headers=headers) UserAgent().random 可以獲取任意瀏覽器的請(qǐng)求頭 UserAgent().Chrome 可以獲取谷歌瀏覽器的請(qǐng)求頭 UserAgent().firefox 可以獲取火狐瀏覽器的請(qǐng)求頭
這個(gè)時(shí)候,直接用random就可以了,簡(jiǎn)單。
讀取內(nèi)存數(shù)組:這個(gè)時(shí)候就有很多人說, 我就換個(gè)請(qǐng)求頭而已,需要這么麻煩嗎? 當(dāng)然,自然有簡(jiǎn)單的方式,只不過每次都需要復(fù)制來用,不是很方法,具體如下:
ua = ['Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.93 Safari/537.36''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/30.0.1599.17 Safari/537.36''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36,Mozilla/5.0 (X11; NetBSD) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.116 Safari/537.36']
預(yù)先把請(qǐng)求頭放入數(shù)組里面,然后用就可以了。
import randomua = [.....]r = requests.get(url, headers={'user-agent':random.choice(ua)})
以上就是我關(guān)于請(qǐng)求頭的幾種設(shè)置方式了,有需要補(bǔ)充的可以評(píng)論區(qū)留言。
教你用三種方式設(shè)置隨機(jī)請(qǐng)求頭, 爬蟲設(shè)置請(qǐng)求頭(user-agent)是必然的,那如何生成一個(gè)隨機(jī)請(qǐng)求頭這個(gè)也是我們爬蟲必須掌握的, 讀完本篇文章你就可以輕松掌握 !
到此這篇關(guān)于python實(shí)現(xiàn)三種隨機(jī)請(qǐng)求頭方式的文章就介紹到這了,更多相關(guān)python 隨機(jī)請(qǐng)求頭內(nèi)容請(qǐng)搜索好吧啦網(wǎng)以前的文章或繼續(xù)瀏覽下面的相關(guān)文章希望大家以后多多支持好吧啦網(wǎng)!
相關(guān)文章:
1. IntelliJ IDEA設(shè)置編碼格式的方法2. docker容器調(diào)用yum報(bào)錯(cuò)的解決辦法3. Docker容器如何更新打包并上傳到阿里云4. idea重置默認(rèn)配置的方法步驟5. .NET使用Moq進(jìn)行單元測(cè)試6. python判斷變量是否為列表的方法7. jBixbe 1.0-alpha 發(fā)布 -- Java 調(diào)試器8. ASP.NET泛型二之泛型的使用方法9. IntelliJ IDEA設(shè)置條件斷點(diǎn)的方法步驟10. ADO存取數(shù)據(jù)庫(kù)時(shí)如何分頁(yè)顯示

 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備