文章詳情頁
網頁爬蟲 - 關于python beautifullsoup解析網頁內容丟失的問題?
瀏覽:124日期:2022-09-23 08:23:07
問題描述
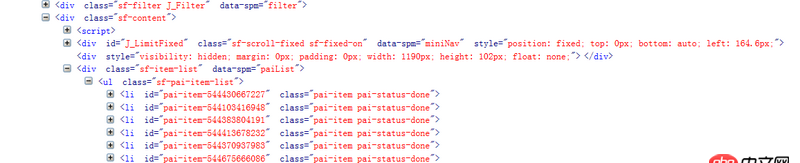
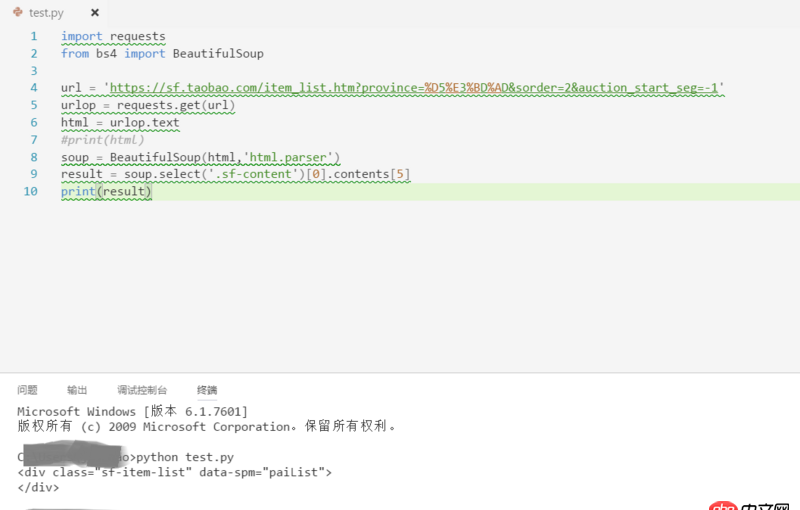
待解析頁面的部分代碼如第一幅圖所示,我自己寫的代碼及運行結果如第二幅圖所示。看到已經有答主提問解析頁面丟失是因為用的是lxml的解析方式,我想說我一直用的是html.parser的方式。希望各位大神不吝賜教~
問題解答
回答1:你們從來都不考慮javascript動態加載的嗎?
回答2:題主,如果你用Chrome F12看的話,里面是會有動態加載的內容的,而這些內容你直接請求頁面的url是拿不到的。建議你點右鍵查看網頁源代碼,對照著F12里面的內容來看,源代碼里沒有的內容,就去查看Network里的其他請求,看有沒有你需要的數據。
相關文章:
1. python - linux怎么在每天的凌晨2點執行一次這個log.py文件2. 關于mysql聯合查詢一對多的顯示結果問題3. 實現bing搜索工具urlAPI提交4. MySQL主鍵沖突時的更新操作和替換操作在功能上有什么差別(如圖)5. 數據庫 - Mysql的存儲過程真的是個坑!求助下面的存儲過程哪里錯啦,實在是找不到哪里的問題了。6. windows誤人子弟啊7. 冒昧問一下,我這php代碼哪里出錯了???8. 如何用筆記本上的apache做微信開發的服務器9. 我在網址中輸入localhost/abc.php顯示的是not found是為什么呢?10. mysql優化 - MySQL如何為配置表建立索引?
排行榜
 網公網安備
網公網安備