文章詳情頁
網(wǎng)頁爬蟲 - Python爬蟲返回狀態(tài)碼與實際情況不符?
瀏覽:201日期:2022-09-03 18:57:11
問題描述
import urllib2opener = urllib2.build_opener()html = Noneresponse = Noneresponse = opener.open(’http://www.sxxrcs.com/was5/web/’)html = response.codeprint html
比如這個爬蟲,輸出狀態(tài)碼是200。
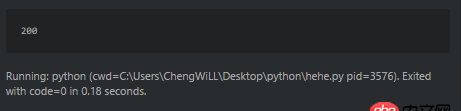
可是直接訪問http://www.sxxrcs.com/was5/web/是404,抓包響應的也是404,請問這是為什么?
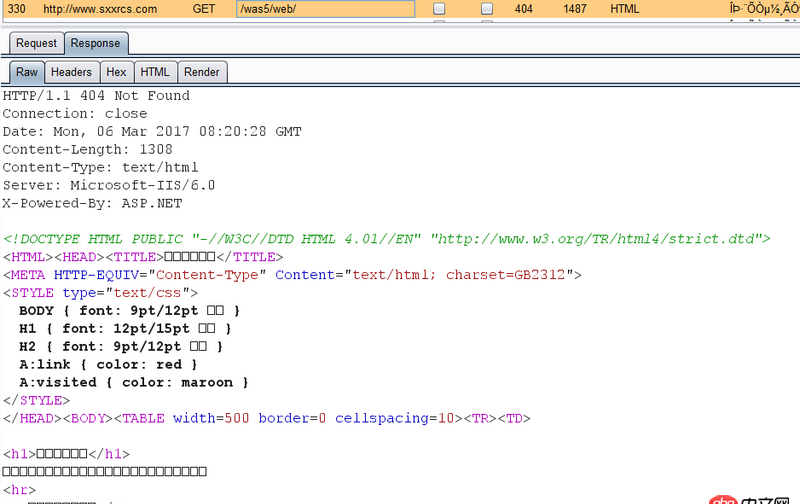
問題解答
回答1:用requests吧
import requestsr = requests.get(’http://www.sxxrcs.com/was5/web/’)print r.status_codeprint r.text回答2:
200正常啊,requests方便快捷。
相關(guān)文章:
1. javascript - 移動端,當出現(xiàn)遮罩層的時候,遮罩層里有div是超出高度scroll的,怎么避免滑動div的時候,body跟隨滑動?2. dockerfile - 為什么docker容器啟動不了?3. javascript - 用rem寫的頁面,安卓手機顯示文字是正常的,蘋果顯示的文字是特別小的是為什么呢4. macos - mac下docker如何設置代理5. 請教各位大佬,瀏覽器點 提交實例為什么沒有反應6. javascript - webapp業(yè)務流程基本一致,多套主題(樣式基本不一樣,交互稍有偏差)管理,并且有不斷有新增主題,該如何設計組件化架構(gòu)?7. apache - 本地搭建wordpress權(quán)限問題8. 新手 - Python 爬蟲 問題 求助9. javascript - 從mysql獲取json數(shù)據(jù),前端怎么處理轉(zhuǎn)換解析json類型10. javascript - JS設置Video視頻對象的currentTime時出現(xiàn)了問題,IE,Edge,火狐,都可以設置,反而chrom卻...
排行榜

熱門標簽
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備