html - Python2 BeautifulSoup 提取網(wǎng)頁中的表格數(shù)據(jù)及連接
問題描述
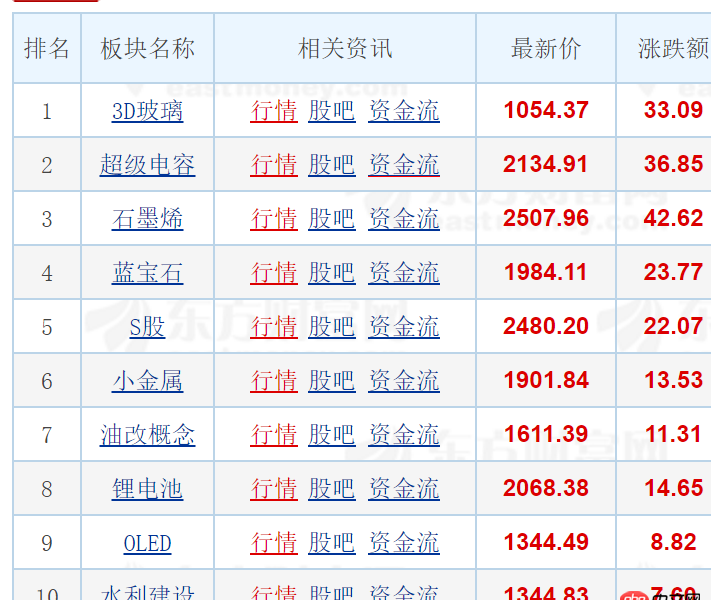
網(wǎng)址:http://quote.eastmoney.com/ce...要做的是提取網(wǎng)頁中的表格數(shù)據(jù)(如:板塊名稱,及相應(yīng)鏈接下的所有個股,依然是個表格)
暫時只寫了這些代碼:import urllib2from bs4 import BeautifulSoup
url=’http://quote.eastmoney.com/ce...’
req=urllib2.Request.(url)page=urllib2.urlopen(req)
soup=BeautifulSoup(page)table = soup.find('table')
但是table里面沒有內(nèi)容,也就是完全沒找到,這是怎么回事啊。po是小白,希望大神們可以多多指教,謝謝!
問題解答
回答1:因為是異步加載,數(shù)據(jù)在這里http://nufm.dfcfw.com/EM_Fina...
# coding:utf-8import requestsr = requests.get(’http://nufm.dfcfw.com/EM_Finance2014NumericApplication/JS.aspx?type=CT&cmd=C._BKGN&sty=FPGBKI&st=c&sr=-1&p=1&ps=5000&token=7bc05d0d4c3c22ef9fca8c2a912d779c&v=0.12043042036331286’)data = [_.decode(’utf-8’).split(’,’) for _ in eval(r.text)]url = ’http://quote.eastmoney.com/center/list.html#28003{}_0_2’lst = [(url.format(_[1].replace(’BK0’, ’’)), _[2]) for _ in data]print lst
相關(guān)文章:
1. php多任務(wù)倒計時求助2. javascript - charles map remote映射問題3. javascript - vue組件的重復(fù)調(diào)用4. tp5.1如何使用獲取器添加自定義字段?5. 數(shù)組排序,并把排序后的值存入到新數(shù)組中6. css - 子元素跑到父元素外面7. 默認輸出類型為json,如何輸出html8. javascript - console.log(typeof(named));的位置不同,第二個為什么會顯示undefined ?9. python的正則怎么同時匹配兩個不同結(jié)果?10. PHP訂單派單系統(tǒng)
 網(wǎng)公網(wǎng)安備
網(wǎng)公網(wǎng)安備