文章詳情頁
python - 使用scrapy框架爬百度圖片被墻
瀏覽:173日期:2022-06-30 14:19:37
問題描述
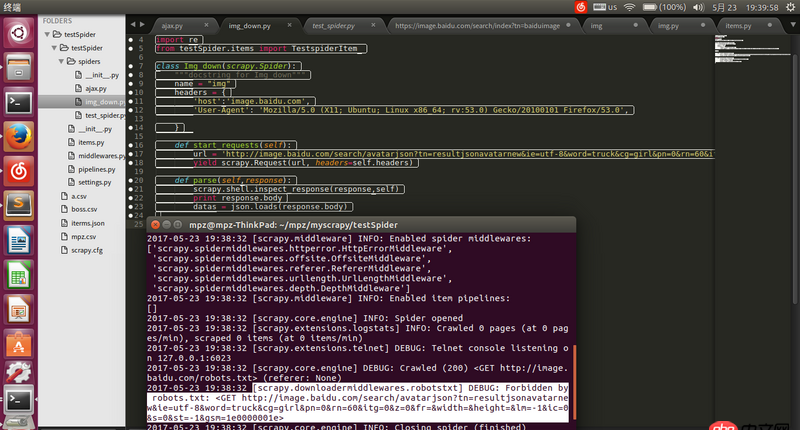
請求地址url是通過firefox查看得到的json的地址,用瀏覽器可以打開,但是用scrapy爬的時候就被ban了求解決辦法。
https://image.baidu.com/searc...
問題解答
回答1:在 settings.py 將 ROBOTSTXT_OBEY = False 試試。
回答2:不要加hearders試試
回答3:贊成樓上,如果還會被墻。可采用scrapy+selenium+phantomjs的方式。
相關文章:
排行榜

 網公網安備
網公網安備